In the day job, I have seen a surprising uptick in the number of OCR-type projects that are coming to us. I had been using document intelligence to mine the label that I want, and overall that works well after you do some fine-tuning. I came across DSPy (Declarative Self-improving Python.) – it is a package that is designed to replace unreliable prompt engineering with structured, modular programming for LLMs. Instead of manually crafting prompts, you write declarative python that specifies what you want the model to do, and DSPy handles the rest.
Note to future self: see this article to expand on this: https://www.e2enetworks.com/blog/chat-with-your-city-steps-to-build-an-ai-chatbot-using-llama-3-and-dspy
Example 1: Structured Ouput (Parsing Emails)
Here is a brief example. We first create a class for the object that we want to extract. This includes creating an input (the email) and the outputs (subject, priority, sentiment, etc):
# ---- Define the task signature -----------------------------------------
# This class describes the structure of the input and expected output fields for the extraction task.
class SupportEmail(dspy.Signature):
# The raw email text to process
email: str = dspy.InputField()
# The extracted subject line
subject: str = dspy.OutputField(desc="Subject line of the email")
# The extracted priority (must be one of: low, medium, high)
priority: Literal["low", "medium", "high"] = dspy.OutputField()
# The product(s) referenced in the email
product: str = dspy.OutputField(desc="The product(s) referenced. Output an empty string if unknown.")
# Whether the email expresses negative sentiment
negative_sentiment: bool = dspy.OutputField(desc="True/False")We then give it sample emails that we want it to parse:
# List of sample support emails to test the extraction
sample_emails = [
"""
Subject: Screen cracked after one week!
Hi team,
I purchased the AlphaTab 11 tablet last Monday and the glass already shattered. I’m extremely disappointed and need a replacement ASAP.
Best,
Carla
""",
"""
Subject: Subscription renewal question
Hello,
My CloudSync Pro plan renewed today and I’d like to switch to monthly billing. Could you advise?
Thanks,
Raj
""",
"""
Subject: Your #1 fan
Loving your alpha tabs. How can I buy more?
xoxo JEFF
""",
]We also need to instantiate a Predict module:
# Create a DSPy prediction module that will extract structured fields from the email
extract_ticket = dspy.Predict(SupportEmail)And lastly, execute the code:
# Main function to run the extraction demo
def main() -> None:
# For each sample email, extract structured fields and print them
for raw in sample_emails:
pred = extract_ticket(email=raw.strip())
print("\n--- Structured Ticket ---")
print(pred)
# Print DSPy history for debugging/inspection
print("\n--- DSPy History ---")
print(dspy.inspect_history())
# Entry point: run main() if this script is executed directly
if __name__ == "__main__":
main()And here is the output:
--- Structured Ticket ---
Prediction(
subject='Screen cracked after one week!',
priority='high',
product='AlphaTab 11 tablet',
negative_sentiment=True
)
--- Structured Ticket ---
Prediction(
subject='Subscription renewal question',
priority='medium',
product='CloudSync Pro',
negative_sentiment=False
)
--- Structured Ticket ---
Prediction(
subject='Your #1 fan',
priority='medium',
product='alpha tabs',
negative_sentiment=False
)
--- DSPy History ---
[2025-09-25T16:30:53.878666]
System message:
Your input fields are:
1. `email` (str):
Your output fields are:
1. `subject` (str): Subject line of the email
2. `priority` (Literal['low', 'medium', 'high']):
3. `product` (str): The product(s) referenced. Output an empty string if unknown.
4. `negative_sentiment` (bool): True/False
All interactions will be structured in the following way, with the appropriate values filled in.
[[ ## email ## ]]
{email}
[[ ## subject ## ]]
{subject}
[[ ## priority ## ]]
{priority} # note: the value you produce must exactly match (no extra characters) one of: low; medium; high
[[ ## product ## ]]
{product}
[[ ## negative_sentiment ## ]]
{negative_sentiment} # note: the value you produce must be True or False
[[ ## completed ## ]]
In adhering to this structure, your objective is:
Given the fields `email`, produce the fields `subject`, `priority`, `product`, `negative_sentiment`.
User message:
[[ ## email ## ]]
Subject: Your #1 fan
Loving your alpha tabs. How can I buy more?
xoxo JEFF
Respond with the corresponding output fields, starting with the field `[[ ## subject ## ]]`, then `[[ ## priority ## ]]` (must be formatted as a valid Python Literal['low', 'medium', 'high']), then `[[ ## product ## ]]`, then `[[ ## negative_sentiment ## ]]` (must be formatted as a valid Python bool), and then ending with the marker for `[[ ## completed ## ]]`.
Response:
[[ ## subject ## ]]
Your #1 fan
[[ ## priority ## ]]
medium
[[ ## product ## ]]
alpha tabs
[[ ## negative_sentiment ## ]]
False
[[ ## completed ## ]]The DSPy History is super interesting – it gives us an example of what it is sending to the LLM.
Example 2: Chain of Thought
This is extremely similar to the first example – the main difference is that we are calling dspy.ChainOfThought instead of dspy.OutputField
class LoanRisk(dspy.Signature):
applicant_profile: str = dspy.InputField()
loan_risk: Literal["low", "medium", "high"] = dspy.OutputField()
approved: bool = dspy.OutputField(desc="approve this person for a loan?")
# risk_checker = dspy.ChainOfThought(
# "applicant_profile: str, age: int, is_male: bool -> loan_risk"
# )
risk_checker = dspy.ChainOfThought(LoanRisk)
sample_profile = """Name: Jane Diaz
Credit score: 612
Annual income: $84k
Existing debt: $55k
Requested amount: $25k
Loan purpose: consolidate credit cards
"""def main():
pred = risk_checker(applicant_profile=sample_profile, age=28, is_male="NO")
print("\n--- DSPy History ---")
print(dspy.inspect_history())
print("\n--- Prediction ---")
print(pred)
if __name__ == "__main__":
main()And here is the result:
--- DSPy History ---
[2025-09-25T17:45:03.327644]
System message:
Your input fields are:
1. `applicant_profile` (str):
Your output fields are:
1. `reasoning` (str):
2. `loan_risk` (Literal['low', 'medium', 'high']):
3. `approved` (bool): approve this person for a loan?
All interactions will be structured in the following way, with the appropriate values filled in.
[[ ## applicant_profile ## ]]
{applicant_profile}
[[ ## reasoning ## ]]
{reasoning}
[[ ## loan_risk ## ]]
{loan_risk} # note: the value you produce must exactly match (no extra characters) one of: low; medium; high
[[ ## approved ## ]]
{approved} # note: the value you produce must be True or False
[[ ## completed ## ]]
In adhering to this structure, your objective is:
Given the fields `applicant_profile`, produce the fields `loan_risk`, `approved`.
User message:
[[ ## applicant_profile ## ]]
Name: Jane Diaz
Credit score: 612
Annual income: $84k
Existing debt: $55k
Requested amount: $25k
Loan purpose: consolidate credit cards
Respond with the corresponding output fields, starting with the field `[[ ## reasoning ## ]]`, then `[[ ## loan_risk ## ]]` (must be formatted as a valid Python Literal['low', 'medium', 'high']), then `[[ ## approved ## ]]` (must be formatted as a valid Python bool), and then ending with the marker for `[[ ## completed ## ]]`.
Response:
[[ ## reasoning ## ]]
Jane Diaz has a credit score of 612, which is considered good. Her annual income of $84k is also above average. However, she currently has existing debt of $55k, which may impact her ability to repay the requested loan amount of $25k for consolidating credit cards.
[[ ## loan_risk ## ]]
medium
[[ ## approved ## ]]
Response:
[[ ## reasoning ## ]]
Jane Diaz has a credit score of 612, which is considered good. Her annual income of $84k is also above average. However, she currently has existing debt of $55k, which may impact her ability to repay the requested loan amount of $25k for consolidating credit cards.
[[ ## loan_risk ## ]]
medium
[[ ## approved ## ]]
Jane Diaz has a credit score of 612, which is considered good. Her annual income of $84k is also above average. However, she currently has existing debt of $55k, which may impact her ability to repay the requested loan amount of $25k for consolidating credit cards.
[[ ## loan_risk ## ]]
medium
[[ ## approved ## ]]
True
[[ ## loan_risk ## ]]
medium
[[ ## approved ## ]]
True
[[ ## approved ## ]]
True
[[ ## approved ## ]]
True
True
[[ ## completed ## ]]
[[ ## completed ## ]]
None
--- Prediction ---
Prediction(
reasoning='Jane Diaz has a credit score of 612, which is considered good. Her annual income of $84k is also above average. However, she currently has existing debt of $55k, which may impact her ability to repay the requested loan amount of $25k for consolidating credit cards.',
loan_risk='medium',
approved=True
)In a real world scenario, we would want to define what a good credit score is (the LLM took the liberty of judging the applicant’s application). We passed in “reasoning” as a parm and the model clearly took it and ran with it.
We can also change it to call Chain of Thought like so:
risk_checker = dspy.ChainOfThought("applicant_profile: str, age: int, is_male: bool -> loan_risk")
# risk_checker = dspy.ChainOfThought(LoanRisk) # this is from the first attempt using a signatureIn this example, we are passing in a string instead of the LoanRisk signature. The key difference here is that passing in the string will result in a single output (passing in a signature allows for multiple outputs).
String signature: Only returns the output field named in the string, with possible extra reasoning if the model chooses to add it. No guarantee of structure or additional fields. Signature class: Returns all output fields you define, with types and descriptions enforced, always structured and predictable.
Example 3: Using with RAG
This is a Retrieval-Augmented Generation (RAG) demo for answering HR questions using a small employee handbook. Here’s what it does:
- Loads a set of handbook text snippets into a corpus.
Uses the sentence-transformers library to create embeddings for each snippet, enabling semantic search.
Lets you ask a question (e.g., “How many PTO days do we get per year?”).
Finds the most relevant handbook passages using embeddings.
Passes the question and retrieved context to a language model (OpenAI or Ollama, depending on your settings).
The model generates an answer using both the context and its own reasoning.
Prints the model’s reasoning, the answer, and a history of the interaction.
In short: It’s a simple HR chatbot that answers questions by searching a handbook and using an LLM to generate a response.
We have a string that contains the data we want to work with:
corpus: list[str] = [
# Employee handbook corpus: each string is a section of the handbook
"Employee Handbook (excerpt, v1.0). Purpose & scope: This handbook sets expectations for all employees,This block sets up semantic search over your handbook corpus using embeddings, so the chatbot can find and use the most relevant information when answering questions. We use sentence transformers so that we don’t have to call a service to get the embeddings:
# ---- Generate embeddings with SentenceTransformers --------------------
from sentence_transformers import SentenceTransformer
# Load a small, fast embedding model from Hugging Face
st_model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2", device="cpu")
# Wrap the encoder for DSPy
embedder = dspy.Embedder(st_model.encode, batch_size=64) # callable encoder
# Build an embeddings retriever for RAG
search = dspy.retrievers.Embeddings(
corpus=corpus, # The handbook corpus
embedder=embedder, # Embedding function
k=3, # Return top-3 most relevant snippets
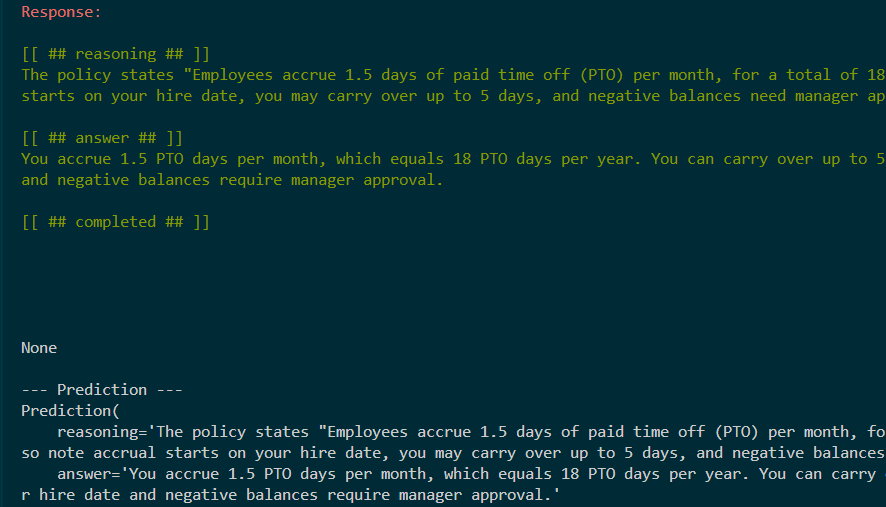
)Notice that a function called “search” is an output.
Here is the output – it found the top 3 (from k) results:
Example 4: ReAct Expense Assistant
We have a few tools defined (don’t use “eval” in production scenarios):
def get_exchange_rate(currency_code: str) -> float:
"""Return USD conversion rate."""
fx = {"USD": 1.0, "EUR": 1.07, "GBP": 1.26}
return fx.get(currency_code.upper(), 0.0)
def calculate(expression: str, yolo: bool = False) -> float:
"""Eval a safe math expression like '123*0.5'."""
if yolo:
print(f"WARNING: Potential unsave eval of '{expression}'")
return eval(expression)
if not re.fullmatch(r"[0-9+\-*/(). ]+", expression):
raise ValueError(f"Unable to evaluate expression '{expression}'")
return eval(expression)We then provide the tools to the model:
exchange_tool = dspy.Tool(get_exchange_rate, name="FX")
calc_tool = dspy.Tool(calculate, name="Calc")
expense_agent = dspy.ReAct(
"prompt -> answer",
tools=[exchange_tool, calc_tool],
)
def main():
q = "I spent 120 EUR on a client dinner. What is that in USD and is it under the $75 per‑person limit?"
pred = expense_agent(prompt=q)
print("\n--- DSPy History ---")
print(dspy.inspect_history())
print("\n--- Prediction ---")
print(pred)
if __name__ == "__main__":
main()And this is the output. Note that it used both tools to answer the prompt:
Response:
[[ ## reasoning ## ]]
I used the provided EUR→USD rate (1.07). 120 EUR × 1.07 = 128.40 USD. Compare $128.40 to the $75 per‑person limit. If multiple people shared the bill, divide $128.40 by the number of people to get per‑person cost; find the minimum number of people needed for the per‑person cost to be ≤ $75.
[[ ## answer ## ]]
120 EUR × 1.07 = $128.40.
- For one person: $128.40 > $75, so it exceeds the $75 per‑person limit (over by $53.40).
- If shared by 2 people: $128.40 ÷ 2 = $64.20 per person → under the $75 limit.
- Minimum number of people required to meet the limit: 2 (since 128.40/75 ≈ 1.71, so you need at least 2 people).
[[ ## completed ## ]]
--- Prediction ---
Prediction(
trajectory={'thought_0': "I'll fetch the current USD conversion rate for EUR so I can convert 120 EUR to USD and compare it to the $75 per-person limit (assuming this is for one person; if multiple people, the per-person amount would change).", 'tool_name_0': 'FX', 'tool_args_0': {'currency_code': 'EUR'}, 'observation_0': 1.07, 'thought_1': "I'll calculate 120 * 1.07 to get the USD amount.", 'tool_name_1': 'Calc', 'tool_args_1': {'expression': '120*1.07', 'yolo': False}, 'observation_1': 128.4, 'thought_2': '120 EUR × 1.07 = $128.40. That exceeds the $75 per-person limit (by $128.40 - $75 = $53.40), so if this was for one person it is not under the limit. If the $128.40 covered multiple people, divide by the number of people to see whether the per-person amount is ≤ $75.', 'tool_name_2': 'finish', 'tool_args_2': {}, 'observation_2': 'Completed.'},
reasoning='I used the provided EUR→USD rate (1.07). 120 EUR × 1.07 = 128.40 USD. Compare $128.40 to the $75 per‑person limit. If multiple people shared the bill, divide $128.40 by the number of people to get per‑person cost; find the minimum number of people needed for the per‑person cost to be ≤ $75.',
answer='120 EUR × 1.07 = $128.40.\n\n- For one person: $128.40 > $75, so it exceeds the $75 per‑person limit (over by $53.40).\n- If shared by 2 people: $128.40 ÷ 2 = $64.20 per person → under the $75 limit.\n- Minimum number of people required to meet the limit: 2 (since 128.40/75 ≈ 1.71, so you need at least 2 people).'
)The trajectory essentially shows how the tools were used.

We can see that “Calc” is called and an expression is passed in. The currency exchange is also called.
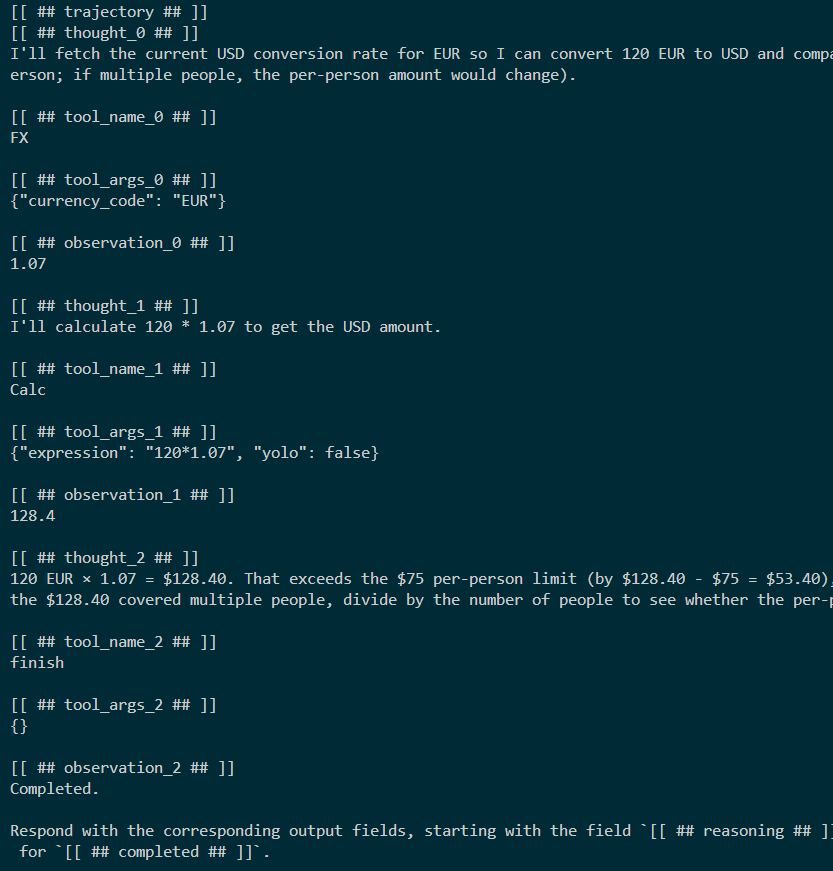
We get a feel for the iterations that went on to answer the prompt. Each step gets the ouput from the previous step.
Example 5: Self-Improving RAG
This file builds a RAG HR Q&A bot, evaluates its accuracy, and then uses DSPy’s self-improving optimizer to automatically make the bot’s answers more precise and match a set of gold-standard answers. It demonstrates how to combine retrieval, LLM reasoning, and automated prompt engineering in a single pipeline.
Possible use case: If you wanted to put this into an endpoint, you would train and optimize the bot AND THEN load an endpoint that pointed to the in-memory bot, all in the same code block.
We are going to optimize a RAG bot with 5 QA examples. Before that, we start with a corpus that is similar to what we saw in the last example:
Same with the sentence transformer:
# ---- Generate embeddings with SentenceTransformers --------------------
from sentence_transformers import SentenceTransformer
st_model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2", device="cpu")
embedder = dspy.Embedder(st_model.encode, batch_size=64) # callable encoder
# Build an embeddings retriever
search = dspy.retrievers.Embeddings(
corpus=corpus,
embedder=embedder,
k=3, # top-k snippets
)
class HRAnswer(dspy.Signature):
"""Answer HR questions using retrieved context, with step-by-step reasoning."""
question: str = dspy.InputField()
context: str = dspy.InputField(desc="relevant handbook snippets")
answer: str = dspy.OutputField()
class MiniHR(dspy.Module):
def __init__(self):
self.answer = dspy.ChainOfThought(HRAnswer)
def forward(self, question: str):
ctx_passages = search(question).passages
context = "\n\n".join(f"- {p}" for p in ctx_passages)
return self.answer(question=question, context=context)
rag_bot = MiniHR()This is where the code starts to differ from the previous examples. We are going to use these example use cases to improve the accuracy (note that they are question/answer pairs!). This is similar to few-shot engineering – we are using these examples to learn from, but they weren’t part of the original creation of the bot:
# ---------------- Eval set --------------------
raw_eval = [
("How many PTO days do we get each year?", "18"),
("Do I need an itemised receipt for a $50 team lunch?", "No"),
("Is beer reimbursable?", "No"),
("What laptop models can new hires choose?", "MacBook Pro and Dell XPS"),
]
devset = [
dspy.Example(question=q, answer=a).with_inputs("question") for q, a in raw_eval
]
# Metric
def exact_match(example: dspy.Example, pred: dspy.Prediction, trace=None) -> int:
return int(pred.answer.strip().lower() == example.answer.strip().lower())This is the loop that iterates through the examples. It starts with the initial RAG bot, and then we are going to evaluate it using the use case examples.
# Helper to run & print a small report
def evaluate_bot(
bot: MiniHR,
dataset: list[dspy.Example],
title: str,
) -> tuple[int, list[tuple[str, str, str, int]]]:
print(f"\n=== {title} ===")
correct = 0
rows = []
for ex in dataset:
pred = bot(question=ex.question)
ok = exact_match(ex, pred)
correct += ok
rows.append((ex.question, pred.answer, ex.answer, ok))
print(
f"- Q: {ex.question}\n → Pred: {pred.answer} | Gold: {ex.answer} | {'✔️' if ok else '✖️'}"
)
print(f"Accuracy: {correct} / {len(dataset)}")
return correct, rowsThis is the optimizer that *should* make our bot more accurate. In this example, we are using the same “devset” for training and testing – this is a bad practice for prod use.
# ---- Optimiser -------------------------------------------------------------
optimizer = dspy.MIPROv2(metric=exact_match, auto="light", verbose=True)
def main():
evaluate_bot(rag_bot, devset, "Baseline")
print("Compiling optimised bot")
optimised_bot = optimizer.compile(rag_bot, trainset=devset, valset=devset)
evaluate_bot(optimised_bot, devset, "Optimized")
print("\n--- DSPy History ---")
print(dspy.inspect_history())
if __name__ == "__main__":
main()Ideally we would have created 3 different datasets:
Part of the output. For each question, the bot gave a detailed, correct-sounding answer, but it did not match the exact expected answer (“Gold”) for any question. The ✖️ symbol means the bot’s answer did not exactly match the gold answer (comparison is strict, e.g., “18” vs. “Each year, employees receive 18 days of paid time off (PTO).”). Accuracy: 0 / 4 means none of the bot’s answers were considered exact matches:
=== Baseline ===
- Q: How many PTO days do we get each year?
→ Pred: Each year, employees receive 18 days of paid time off (PTO). | Gold: 18 | ✖️
- Q: Do I need an itemised receipt for a $50 team lunch?
→ Pred: No, you do not need an itemized receipt for a $50 team lunch as it falls under the limit of $75 where itemized receipts are not necessary. | Gold: No | ✖️
- Q: Is beer reimbursable?
→ Pred: No, beer is not reimbursable according to the company expense & travel policy. | Gold: No | ✖️
- Q: What laptop models can new hires choose?
→ Pred: New hires can choose between a MacBook Pro or a Dell XPS laptop model. | Gold: MacBook Pro and Dell XPS | ✖️
Accuracy: 0 / 4
Compiling optimised bot
2025/09/26 13:50:30 INFO dspy.teleprompt.mipro_optimizer_v2:
RUNNING WITH THE FOLLOWING LIGHT AUTO RUN SETTINGS:
num_trials: 10
minibatch: False
num_fewshot_candidates: 6
num_instruct_candidates: 3
valset size: 4The bot is retrieving relevant information and answering correctly in natural language, but the evaluation metric (exact_match) requires the answer to match the gold answer exactly (case and whitespace normalized). This strict metric is useful for optimization, but it penalizes answers that are correct but phrased differently. The optimizer will now try to improve the bot’s output to better match the expected answers.
Now the optimization process begins. The optimizer is preparing training data (few-shot examples) by running your questions through the bot and collecting its reasoning and answers. These examples will be used to improve the bot’s accuracy in the next steps of optimization. This is a normal part of the DSPy self-improvement pipeline.
2025/09/26 13:50:30 INFO dspy.teleprompt.mipro_optimizer_v2:
==> STEP 1: BOOTSTRAP FEWSHOT EXAMPLES <==
2025/09/26 13:50:30 INFO dspy.teleprompt.mipro_optimizer_v2: These will be used as few-shot example candidates for our program and for creating instructions.
2025/09/26 13:50:30 INFO dspy.teleprompt.mipro_optimizer_v2: Bootstrapping N=6 sets of demonstrations...
Bootstrapping set 1/6
Bootstrapping set 2/6
Bootstrapping set 3/6
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:58<00:00, 14.51s/it]
Bootstrapped 1 full traces after 3 examples for up to 1 rounds, amounting to 4 attempts.
Bootstrapping set 4/6
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:59<00:00, 14.87s/it]
Bootstrapped 2 full traces after 3 examples for up to 1 rounds, amounting to 4 attempts.
Bootstrapping set 5/6
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:29<00:00, 7.48s/it]
Bootstrapped 1 full traces after 3 examples for up to 1 rounds, amounting to 4 attempts.
Bootstrapping set 6/6
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:43<00:00, 10.92s/it]
Bootstrapped 1 full traces after 3 examples for up to 1 rounds, amounting to 4 attempts.
2025/09/26 13:53:41 INFO dspy.teleprompt.mipro_optimizer_v2:The optimizer is generating possible instructions (prompts) to guide the model toward producing more accurate, concise answers. How does it do this? It uses:
- The few-shot examples bootstrapped in STEP 1 (sample Q&A pairs).
- A summary of your dataset (the types of questions and answers).
- A summary of your program code (the structure of your Signature and Module).
- A randomly selected prompting tip (best practices for prompt engineering).
It also prints out the relevant parts of your code, including the Signature fields and their descriptions, so it can generate instructions that match your intended output format.
==> STEP 2: PROPOSE INSTRUCTION CANDIDATES <==
2025/09/26 13:53:41 INFO dspy.teleprompt.mipro_optimizer_v2: We will use the few-shot examples from the previous step, a generated dataset summary, a summary of the program code, and a randomly selected prompting tip to propose instructions.
SOURCE CODE: StringSignature(question, context -> reasoning, answer
instructions='Answer HR questions using retrieved context, with step-by-step reasoning.'
question = Field(annotation=str required=True json_schema_extra={'__dspy_field_type': 'input', 'prefix': 'Question:', 'desc': '${question}'})
context = Field(annotation=str required=True json_schema_extra={'desc': 'relevant handbook snippets', '__dspy_field_type': 'input', 'prefix': 'Context:'})
reasoning = Field(annotation=str required=True json_schema_extra={'prefix': "Reasoning: Let's think step by step in order to", 'desc': '${reasoning}', '__dspy_field_type': 'output'})
answer = Field(annotation=str required=True json_schema_extra={'__dspy_field_type': 'output', 'prefix': 'Answer:', 'desc': '${answer}'})
)
class MiniHR(dspy.Module):
def __init__(self):
self.answer = dspy.ChainOfThought(HRAnswer)
def forward(self, question: str):
ctx_passages = search(question).passages
context = "\n\n".join(f"- {p}" for p in ctx_passages)
return self.answer(question=question, context=context)Response:
[[ ## reasoning ## ]]
The context provided states that "New hires choose between a MacBook Pro and a Dell XPS" in the Equipment & security section.
[[ ## answer ## ]]
MacBook Pro and Dell XPS
[[ ## completed ## ]]As of 2.6, we can save the bot and then later load it so that it can be executed in code:
optimised_bot = optimizer.compile(rag_bot, trainset=devset, valset=devset)
optimised_bot.save("./dspy_program_directory/", save_program=True)
import dspy
loaded_bot = dspy.load("./dspy_program_directory/")
# Use loaded_bot(question="...") in your endpoint