As you might know, I have a server affectionately known as HAL that serves as the backbone for everything that goes on in my home and in my development. I have a full docker environment will a couple dozen containers that provide numerous services for the home and for my playtime. When local LLMs started to become popular, I bought a respectable video card (nVidia RTX 3060) and had a container full of LLMs. This was great, for a while. I have a variety of apps calling various models, and that worked well until my environment became too big for that container. The 3060 allows LLMs to be loaded into VRAM, but this doesn’t help much when you have uses cases that require a variety of LLMs (chat completion, function calling, coding assistance, speech, etc). I decided to split off the majority of this work onto another server (HP ProDesk 800 G4 MT UP TO Intel i7-8700 64GB RAM). I might still add a video card later – I am curious to see how this performs.
Since it is a LOT cheaper to buy RAM instead of a video card, I took a different approach with this build. Instead of buying a card and loading more models into VRAM, I decided to instead load quantized models into RAM. While this not as efficient as going the GPU route, is should be *good enough* to satisfy most of my use cases. Also, taking this approach is still worlds faster than waiting for Ollama to load a new model in the current Ollama instance on HAL.
After doing a lot of research, I decided to continue to use Ollama on the new server. Each LLM will have its own container, and each container will have its own port. Also, I added a little code to ensure that the models are loaded into memory when the container loads.
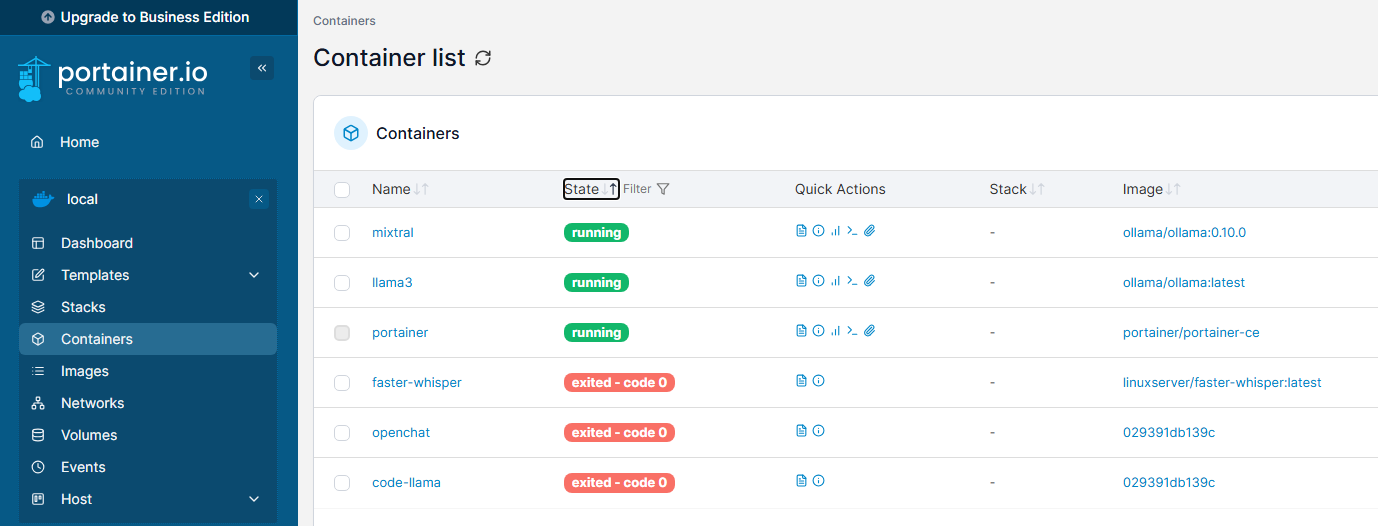
I am still in the midst of spinning up each container – I prioritized llama and mixtral as they are most commonly used.

The quantized model is loaded into memory.





