I know that I sound like a broken record when I say this – I love mixing passions. A couple of years ago I decided to make the jump into AI, but I have been a fan of movies for almost two decades. I review movies at my website IHATEBadMovies.com and at this writing I have over 1,500 reviews. If you feel so inclined, you can find my code here.
As part of my AI / Machine Learning journey, I decided that I wanted to take a deeper dive into recommendation systems. I am sure that you know have seen them before: if you are in Netflix, you’ll see a “movies you might like” list. Same thing on Amazon and countless other sites. But what is behind them?
There are several different types of recommendation systems. Two of the ones you will see most often are Collaborative Filtering and Content-Based Filtering.
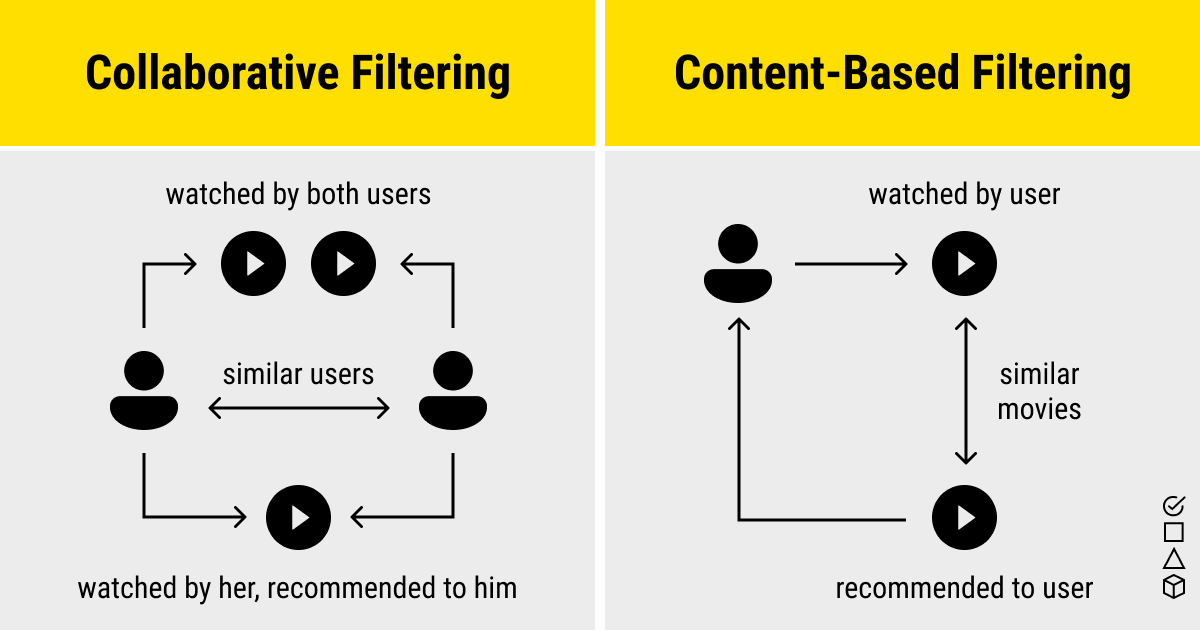
Collaborative filtering is the practice of finding users that like similar movies to you, and then recommending the movies that those reviewers liked. Content-based filtering finds items similar to an item that you like. The great thing about this filtering is that they are NOT specific to any specific category. I could compare movies, recipes, songs, etc, and it would work the same with all of them.
Collaborative Filtering
Imagine living in a neighborhood where your neighbors all like the same movies that you do. For an introverted movie lover like me, that sounds like heaven. On Saturday afternoon, you could just pop your head out the door to ask what should be watched that evening.
In the machine learning world, this is known as “K Nearest Neighbor”. In short, people are grouped together based on similar likes. This is a VERY common technique in machine learning and is not specific to recommendation systems.
So how does this help me find a movie on a saturday night? The answer is simple, but getting there requires a bit more explanation. In order to find my like-minded brothers and sisters, I need a metric crap ton of movie reviews. The availability of of such data is much of the reason that AI has boomed in the last several years (the math behind machine learning goes back many decades). There are several such datasets available to us today – I chose to use MovieLens’ dataset that contains 25 million reviews.
Assembling the Data
Here is a dirty little secret about programming and data science: the bulk of the work is done in setting up the data. The part that actually does the magic (in this case, creating the model to recommend the movies) is actually only a few lines of code.
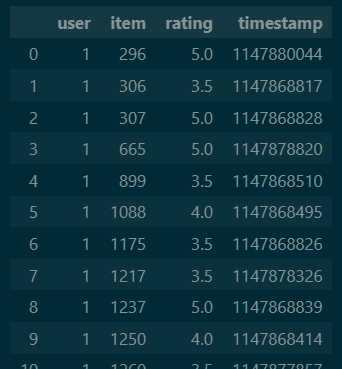
The 25 million movie reviews come in this format
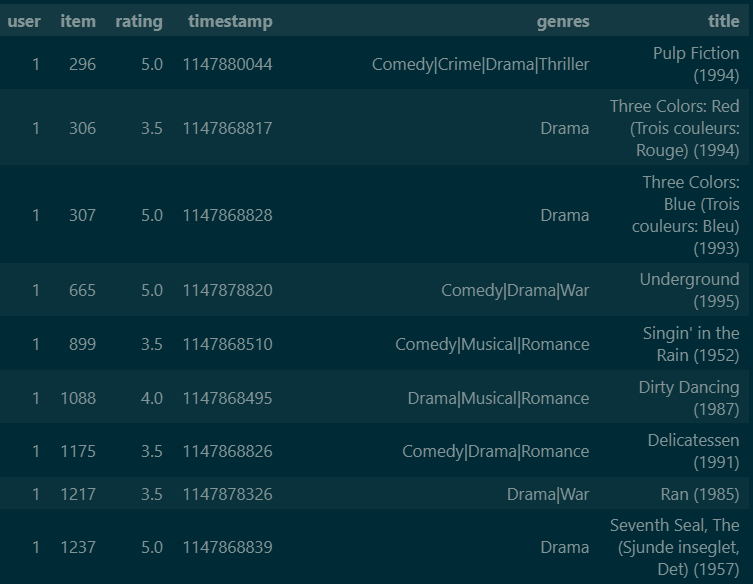
After some work with other files that contain the information for the movies, we have a dataset that looks like this.
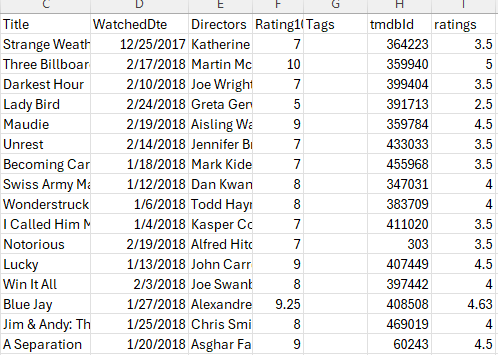
An extract from my review site. Note that the ratings have to be converted to be base 5.
The code for all of this can be found in the repo that I referenced earlier. I’ll (mostly) spare you that here, but I would like to go over the basic steps.
- Read in the files (25 million anonymous reviews, movie information, my personal reviews).
- Clean up / normalize the data. A good data engineer must be able to analyze and understand the data before it can be used in a model. In this exercise, I can see that there are dozens of 5 star reviews where the review was the only one for that particular movie. This would have significantly skewed my model as these movies would have been weighted the same as movies that had hundreds of reviews. So I had to drop all instances where a movie had less than x reviews.
- Find my nearest neighbors. Believe it or not, a very small amount of code to was used to make this happen.
from lenskit.algorithms import Recommender from lenskit.algorithms.user_knn import UserUser user_user = UserUser(15, min_nbrs=3) #These two numbers set the minimum (3) and maximum (15) number of neighbors to consider. These are considered "reasonable defaults" algo = Recommender.adapt(user_user) algo.fit(data.ratings) # this essentially "trains" s user-user CF model. The ratings data are memorized in a format that is usable for computations - Call the model to get the results. Again, this was only a few lines of code.
reviewer1_recs = algo.recommend(-1, num_recs, ratings=pd.Series(reviewer1_rating_dict)) joined_data = reviewer1_recs.join(data.movies['genres'], on='item') joined_data = joined_data.join(data.movies['title'], on='item') joined_data = joined_data[joined_data.columns[2:]]
Results: Minimum of 50 Reviews
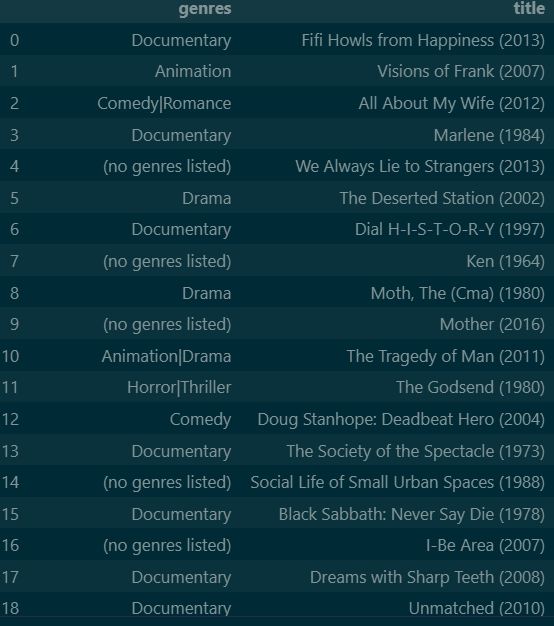
When I specified that the script should only consider a movie with at least 50 reviews, this is what I got back. I haven’t heard of most of these movies, which is very interesting because I watch a fair amount of off-the-beaten path foreign and indie movies. It isn’t surprising that the model put me in a neighborhood with people that like these kinds of movies.
Lets take a look at one of the movies on the list:
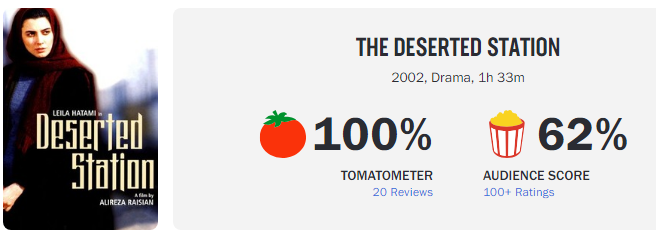
This turns out to be an Iranian movie, and I have previously enjoyed many movies from this country.

Yeah, this sounds right up my alley.
Content-Based Filtering
But what if I wanted to simply find movies that are similar to a single movie that I like? This would fall into the class of content-based filtering. I created a separate script (repo listed at the beginning of this article) and pulled in the same datasets.
Correlation
One of the keys to this kind of filtering is to find how similar one item is when compared to another. So for example, lets see what happens when we compare “Star Wars” with other movies in our list.
And the result is this:
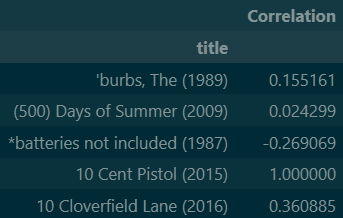
Now just to be clear, these are NOT movies similar to Star Wars. For demonstration purposes, I compared Star Wars to the first 5 movies in the table in order to get a correlation score. The range here is from -1 to 1, and a positive score indicates some level of similarity. The closer the value is to 1, the more similar two movies are expected to be. You might also notice that “10 Cent Pistol” is rated as a perfect match for Star Wars….

Um….. yeah. Forget the ratings – I am not sure why a mystery/crime/thriller would be considered similar to Star Wars.
The Results
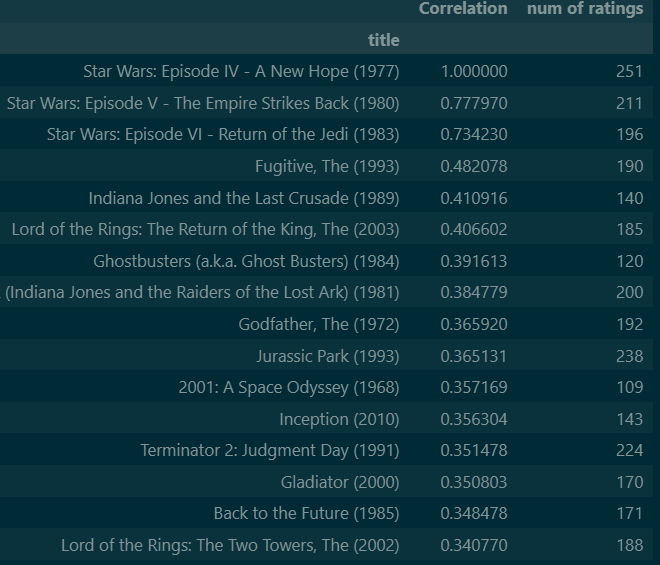
I purposely did not filter out Star Wars – not surprisingly, it is a match with itself. Please note that these recommendations are NOT based on my personal reviews. They are based on items that the algorithm considers to be similar. How does it know? Well, the short answer is that the algorithms are essentially a black box loaded with math. The good news is that you generally don’t have to understand the math. The bad news is that it might be tough to explain why Star Wars is considered very similar to 10 Cent Pistol.